Help us double down on what's working, instead of guessing. Takes 5 seconds, totally optional.
The 33% of Data That Broke Our SVI Fits - A Liquidity Filtering Experiment
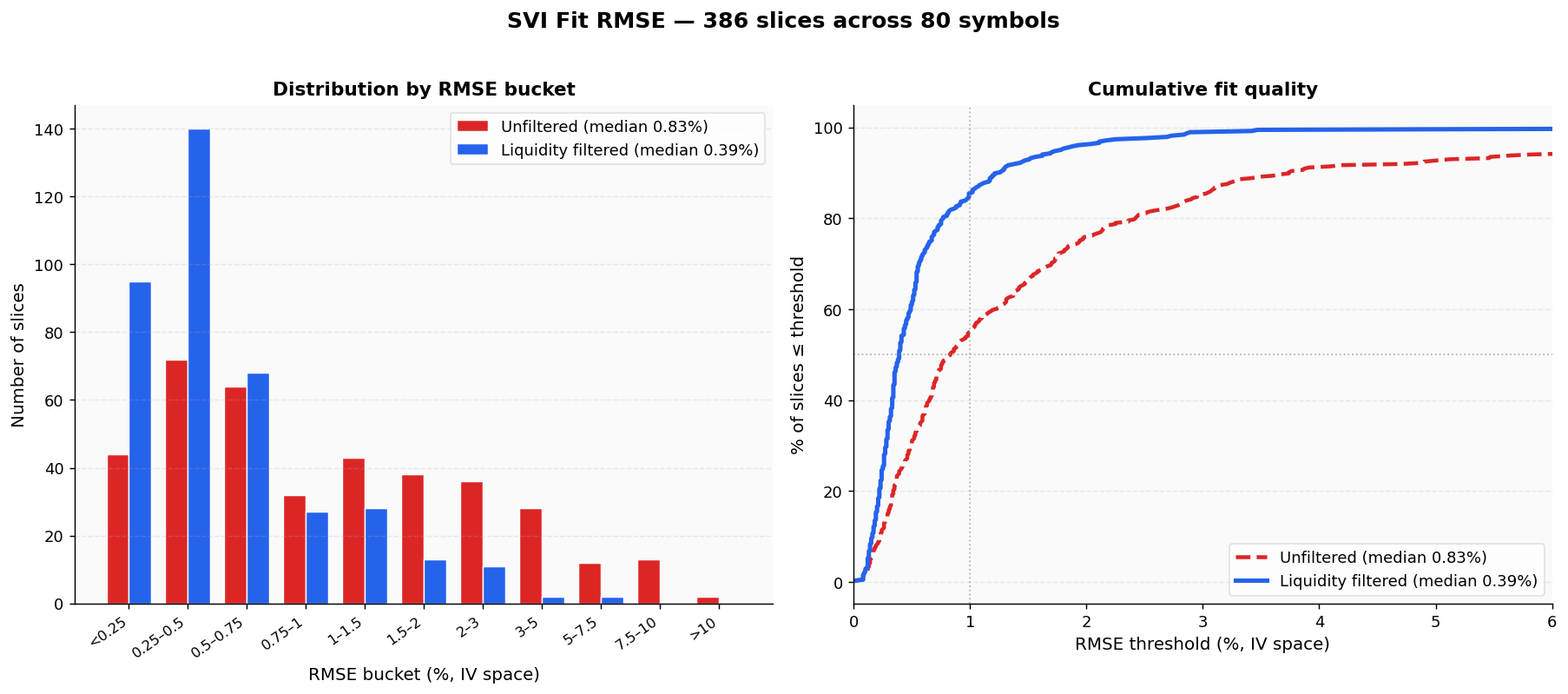
We captured 386 option chain slices across 80 symbols and tested whether dropping zero-bid and wide-spread quotes improves SVI calibration. Median RMSE fell from 0.83% to 0.39% in IV space, the worst fit went from 35% to under 1%, and the pathological short-DTE fits that were blowing up got fixed.
A user reported that our SVI fits were overshooting on the wings for certain expiries. The story was a familiar one for anyone who has shipped a vol-surface pipeline - the curve looked great near the money, then drifted away from market as you moved into the far OTM puts and deep OTM calls.
The Hypothesis
The SVI optimizer was being pulled around by quotes that had no real market behind them - zero-bid options where only the ask side was ticking, and wide-spread contracts where the mid price was fiction. These phantom points were anchoring the fit in places the market never actually traded.
The question was straightforward - if we drop the untradeable points before fitting, does the fit actually get better? And by how much? This post is the experimental answer.
This filter is already running in production for every SVI fit returned by our Advanced Volatility endpoint. If you want the calibrated surfaces described in this article without building your own pipeline, you can pull them with a single API call on the Alpha plan.
2. The Experiment
We captured full option chains for 80 symbols during a live US trading session, picking a deliberate cross-section:
Healthcare (7): JNJ, PFE, LLY, MRK, UNH, GILD, BIIB - can have noisy far wings
Consumer (7): WMT, TGT, COST, NKE, SBUX, MCD, HD
For each symbol we took 5 expiries spanning the term structure (shortest available, ~1 month, ~3 months, ~6 months, ~1 year LEAP). After requiring at least 5 liquid points per slice, we had 386 valid slices totaling 17,712 OTM option points.
Two Fits Per Slice
For each slice we fit raw SVI twice. Fit A uses every OTM quote that passes the existing moneyness and IV-bounds filter. Fit B additionally drops quotes where the bid is zero, or where the bid-ask spread exceeds 50% of the mid price. We then measure both fits using RMSE in IV space against the liquid subset - the points we trust.
The liquidity filter is deliberately simple. Two rules:
No OI threshold, no volume threshold, nothing about delta. Just - is there a real bid, and is the spread under 50% of the mid.
3. Aggregate Results
Massive improvement. Here are the numbers across 386 slices and 17,712 OTM option points spanning 80 symbols:
Metric
Unfiltered
Liquidity Filtered
Change
Median RMSE
0.83%
0.39%
−53%
Average RMSE
1.74%
0.60%
−66%
Max RMSE
35.28%
6.81%
−81%
RMSE < 1% (excellent)
212/386 (55%)
330/386 (85%)
+118
RMSE < 2% (good)
293/386 (76%)
371/386 (96%)
+78
Impact distribution: 231 slices improved, 151 unchanged, only 4 worsened.
Points dropped: 5,829 / 17,712 (32.9%) - nearly a third of every captured chain was effectively noise that pulled the fit around without representing real market prices.
−53%
median RMSE (0.83% → 0.39%)
−81%
worst-case RMSE (35.28% → 6.81%)
96%
of slices now fit under 2% RMSE
231/386
slices improved, only 4 worsened
Here is the full histogram of fit RMSE across all 386 slices - unfiltered in red, liquidity-filtered in blue:
The Pareto Lesson
Throwing away 33% of the data made the median fit 53% better, the worst case 81% better, and lifted the share of "excellent" (<1% RMSE) fits from 55% to 85%. This is a data-quality story, not a model story - the SVI parameterization was fine all along. It was being asked to fit noise.
4. Where the Improvement Came From
The tail of the RMSE distribution is where the drama lives. Looking at the top 20 most improved slices, every single one was a short-dated expiry (3-48 DTE). The long-dated options already had clean, liquid chains - the filter didn't change anything because nothing was illiquid to begin with.
Short DTE is a different world. The wings of a 6-DTE chain are full of deep OTM options quoted at 0.01 × 0.02 by a market maker with no genuine interest - they are placeholder quotes. Compute an implied vol from 0.01 × 0.02 and you get a number, but that number reflects tick size quantization, not market consensus.
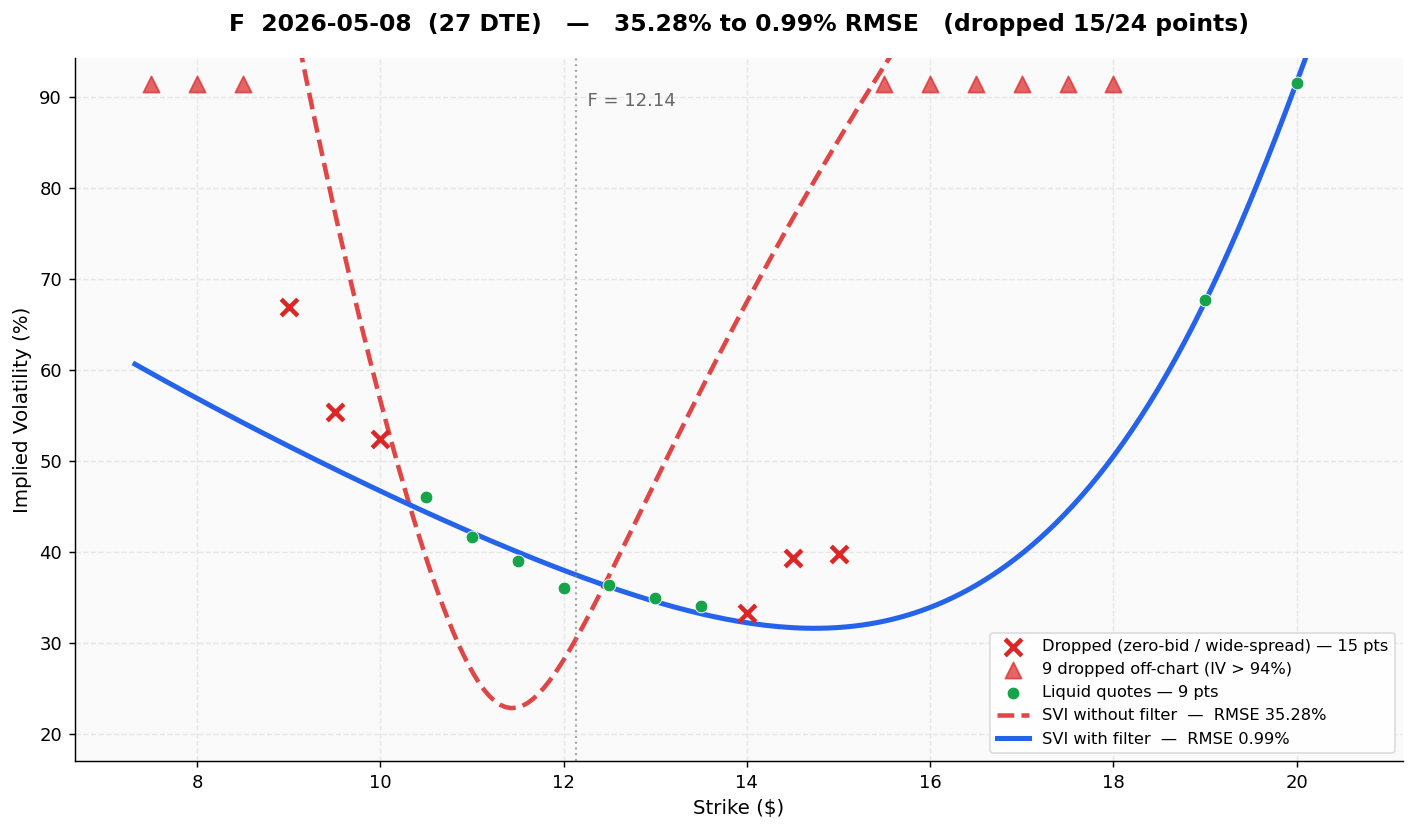
4.1 F (Ford), 27 DTE - RMSE 35.28% → 0.99%
The single worst fit in the entire 386-slice dataset. Ford on a 27-day expiry. The liquid belly is a tight cluster of 9 quotes around the forward, but the unfiltered fit was dragged into a wild U-shape by 15 ghost quotes on both wings. Throwing away the wings collapsed the error from 35% to under 1%:
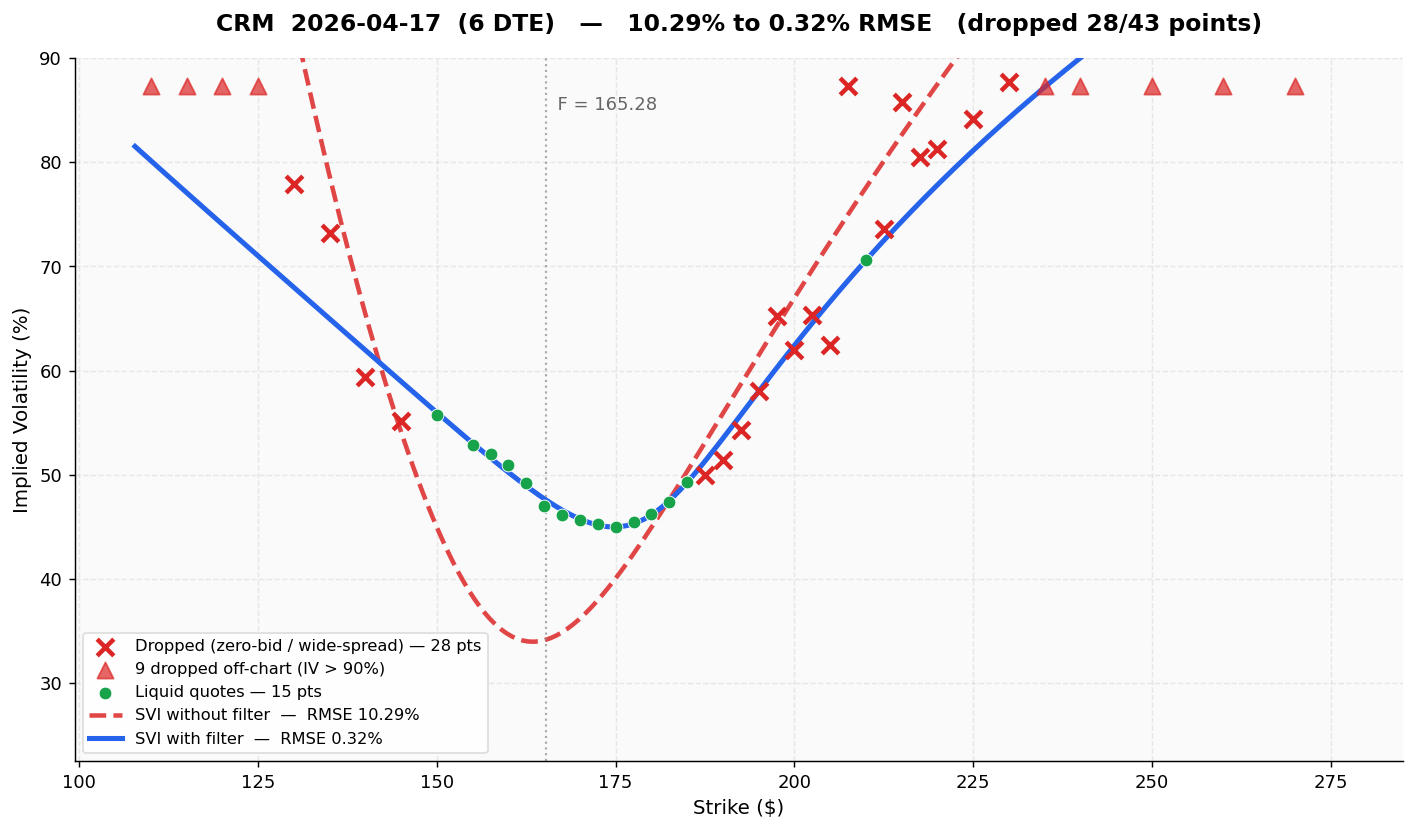
4.2 CRM (Salesforce), 6 DTE - RMSE 10.29% → 0.32%
CRM on a 6-day expiry - a large-cap tech name you would expect to have clean options data. Yet 28 of 43 OTM quotes (65%) failed the liquidity filter. The filtered SVI threads through the liquid cluster almost exactly (0.32% is near the numerical floor):
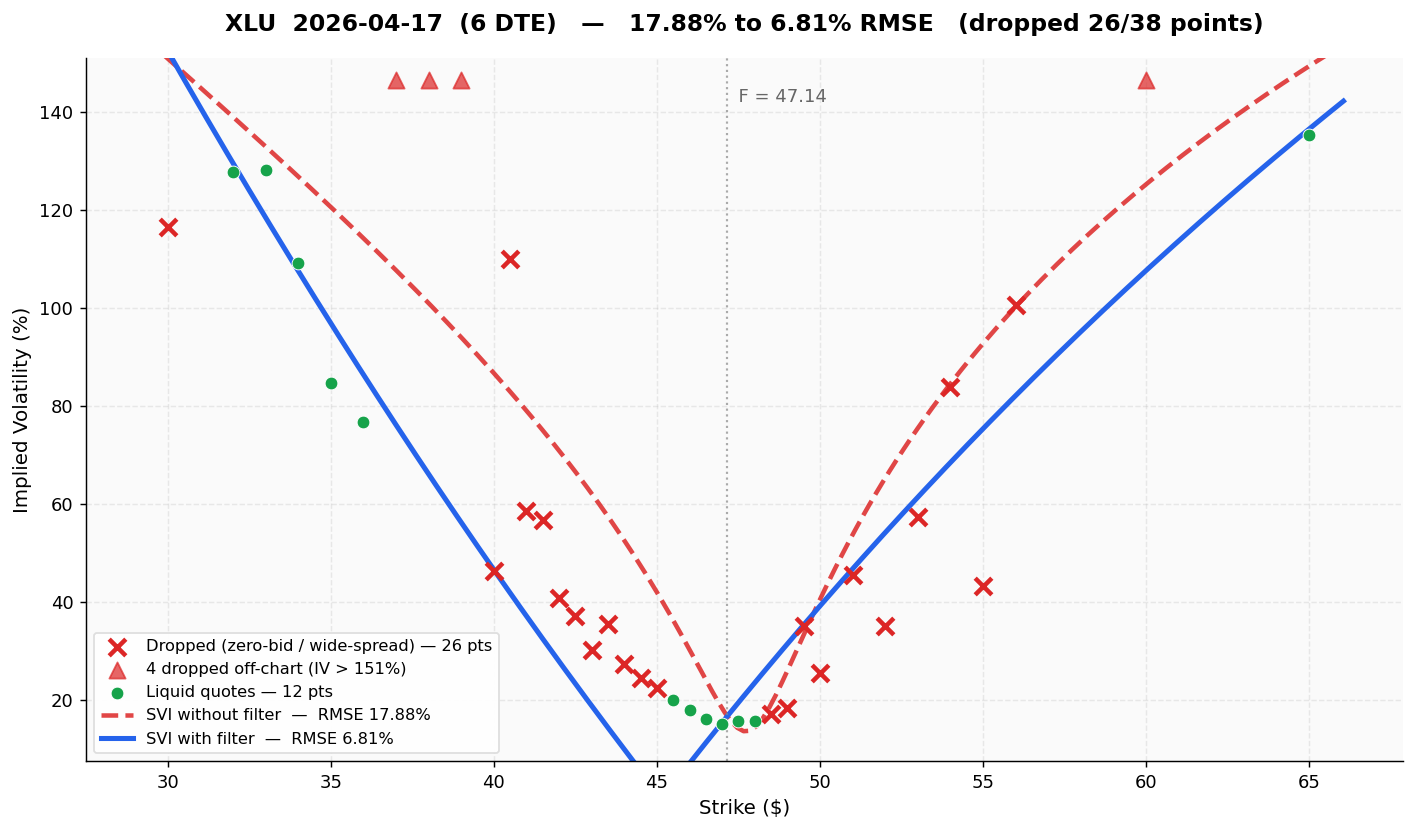
A low-beta sector ETF where the wings are sparse and most of the OTM quotes on a 6-DTE chain are ask-only. Even after filtering, 6.81% RMSE is the highest residual in the filtered column - XLU's short-dated smile is genuinely hard to fit because there just is not enough real data to anchor the wings:
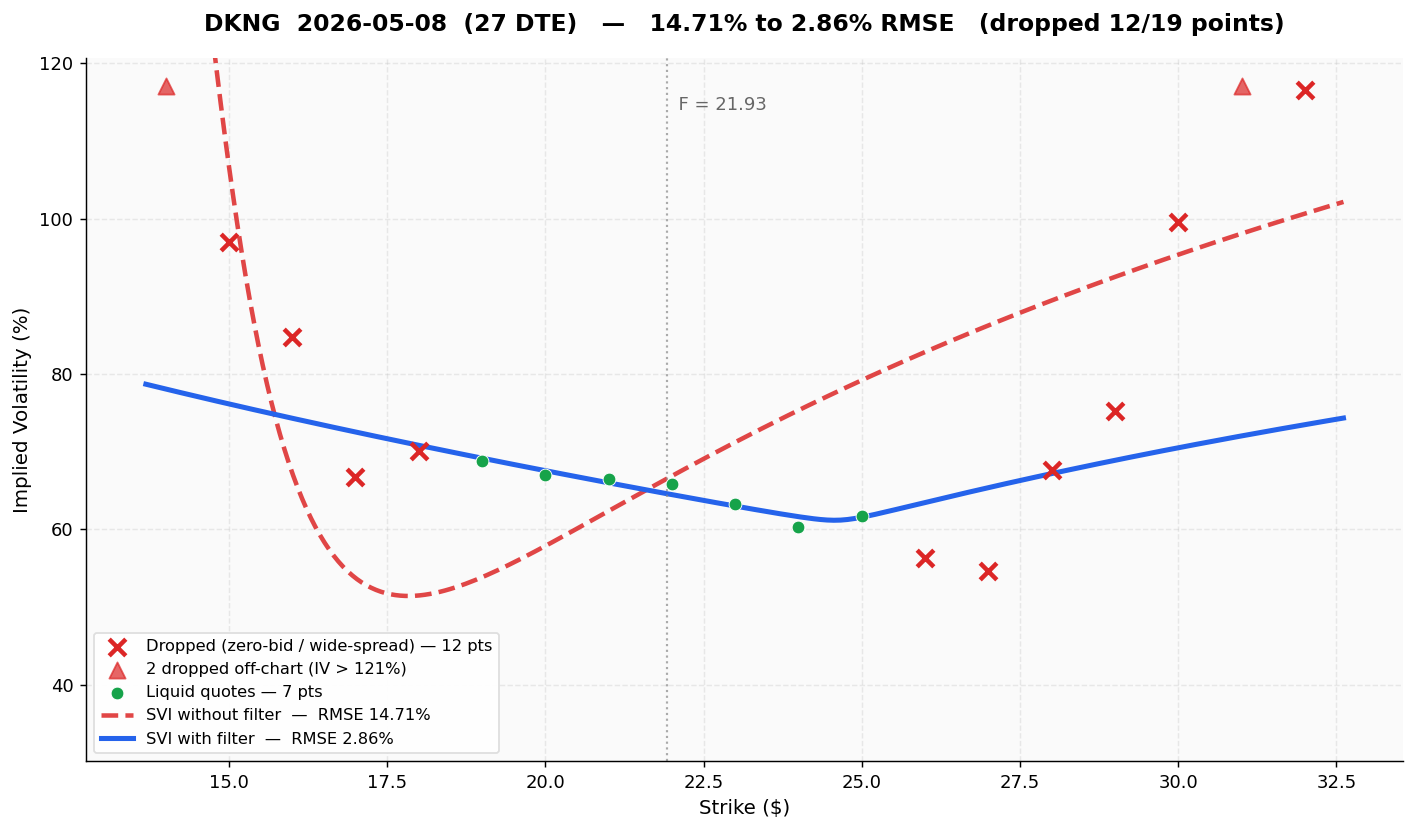
A volatile single name on a 27-day expiry. Even at a month out, 12 of 19 OTM quotes on DKNG were pure noise. The unfiltered SVI forms a distorted parabola trying to reconcile them; the filtered SVI is a clean smile through the 7 surviving liquid points:
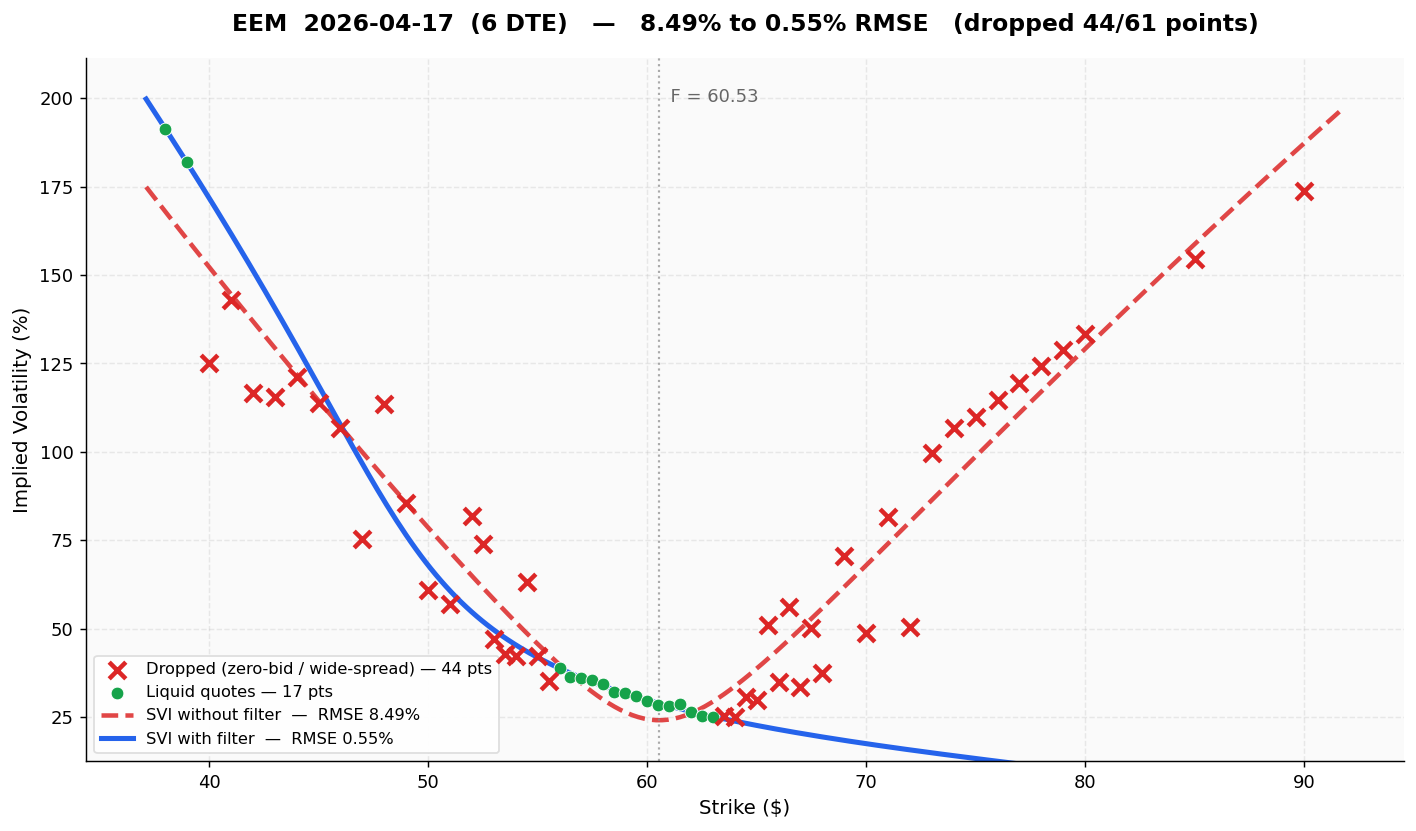
EEM has a notoriously thin far-OTM call wing. The unfiltered fit is a compromise between reality and the zero-bid noise; after filtering, the SVI is essentially exact on the liquid points (0.55%):
5. Why This Works - The Optimization View
Raw SVI fits 5 parameters \((a, b, \rho, m, \sigma)\) by minimizing squared error in total variance space. Every input point contributes equally to the loss function. A zero-bid option with a phantom IV of 130% pulls the optimizer with the same force as a liquid ATM option whose IV is anchored by real trading.
The Objective Mismatch
The SVI fitter is a least-squares solver. It does exactly what you tell it - minimize the sum of squared residuals. If half your residuals are computed from ghost quotes, the solver will happily compromise the fit in the regions that matter (ATM, near-ATM) to reduce error in regions that do not matter (far OTM, illiquid). Liquidity filtering fixes this at the input layer.
An alternative is to keep all points but weight them by something like 1/spread or BS vega. We tried vega weighting first - it looked elegant in theory but actually worsened wing behaviour because far-OTM options have tiny vega, so weighting further de-emphasized the wings. The opposite of what we wanted.
Hard-filtering illiquid quotes is a categorically better solution than soft weighting when the underlying issue is that the data is wrong, not just noisy. A zero-bid is not a weak signal - it is not a signal.
6. What Did NOT Change
We want to be honest about the limits of this experiment:
Long-dated expiries were already fine. For any slice with DTE > 90, the filter typically dropped zero points and the RMSE stayed identical. Liquidity on LEAPs is fine.
The SVI parameterization did not change. Same 5 parameters, same Nelder-Mead optimizer, same Roger Lee wing constraints. All we changed was the input set.
We did not fix the fundamental model limits. SVI is a 5-parameter curve. If you have a smile that cannot be described by a shifted hyperbola, filtering data will not save you. SSVI or SABR would be required.
Spread threshold is a design choice. We used 50% as the cutoff. Tighter (e.g., 30%) drops more data and risks losing legitimate low-liquidity points on illiquid underlyings. Looser (e.g., 100%) lets more noise through. 50% was a round number that worked well empirically.
7. Implementation
The change to our production pipeline was six lines of code. We apply the filter inside the per-expiry fitting loop, right after the OTM-only filter and before creating the SVI input points:
That is the entire change. No new parameters to tune, no new dependencies, no new failure modes. The filter runs in O(1) per option, so there is no performance impact at all.
8. Takeaways
Lessons from 17,712 points across 80 symbols
Data quality dominates model choice at short DTE. A simple SVI on clean data beats a sophisticated model on dirty data, every time.
Zero-bid quotes are not low-information points - they are non-points. Treating them as data is a category error.
The 50% spread rule is a surprisingly effective universal filter. It catches market-maker ghost quotes without rejecting legitimately illiquid-but-real markets.
Measure before you optimize. We were about to implement SSVI, a much more invasive change, before running this experiment. A one-day data-quality intervention captured most of the improvement SSVI would have delivered, at a tiny fraction of the complexity.
Long-dated expiries did not need this fix. The filter is a surgical instrument for short-DTE noise - it changed nothing on clean LEAP data.
If you are running an SVI calibration pipeline and have not looked at your input data lately, look now. Count how many of your fitted points have a bid of zero. You might be surprised how much of your fit error is being generated by options that no one would ever trade.
9. Skip the Pipeline
Everything described in this article - the OTM-only filter, the bid/ask liquidity check, the multi-start Nelder-Mead SVI fitter with Roger Lee wing constraints, the Alpha+ cache-bypass for fresh surfaces - is already running in production. The calibrated SVI parameters, forward prices, total-variance grids, and arbitrage checks are delivered by a single API call:
from flashalpha import FlashAlpha
fa = FlashAlpha("YOUR_API_KEY")
surface = fa.adv_volatility("SPY")
for slice in surface.svi_parameters:
print(f"{slice.expiry}: a={slice.a:.4f} b={slice.b:.4f} "
f"rho={slice.rho:+.4f} m={slice.m:.4f} sigma={slice.sigma:.4f}")
You get raw SVI parameters for every expiry, forward prices from put-call parity, a dense total-variance surface you can interpolate, butterfly/calendar arbitrage flags, variance swap fair values, and greeks surfaces (vanna, charm, volga, speed). The liquidity filter described in this article runs automatically before each fit - you benefit from the improvement without implementing it.
αAlpha Plan
The Advanced Volatility endpoint is available on the Alpha plan: SVI-calibrated surfaces with liquidity-filtered fits, zero cache, arbitrage detection, variance swap pricing, and dedicated support. Everything in this article, as a single REST call.
Questions about integration or want to discuss your use case? Reach out at [email protected].
If you are currently maintaining your own SVI pipeline, run the experiment from this article against your own fits. If our surfaces match or exceed yours with a single HTTP call, you have just eliminated a meaningful chunk of engineering maintenance.
One-third of our captured chain was unfittable noise - zero-bid ghost quotes and spreads wider than half the mid. Dropping all of them cut median fit error by half and the worst-case fit by 81%. Sometimes the best model improvement is a better input. This is a data-quality story, not a quant one - and it ships as part of every Advanced Volatility API call on the Alpha plan.